Some basic experimental designs
Completely randomised design (CRD)
Let’s consider a completely randomized design with one treatment factor (e.g., coffee bean type). Here, \(n\) experimental units (e.g., cups) are divided randomly into \(t\) groups. Random allocation can be achieved by simply drawing lots from a hat! To be more rigorous, though, we could use R’s sample() function (have a go yourself and see if you can work out how to wield sample()). Each group is then given one treatment level (one of the treatment factors). As we have defined only one treatment factor all other known independent variables are kept constant so as to not bias any effects.

Designing a CRD using R
Here we’re going to use R to do the random allocation of treatments for us.
## create a character vector of bean types
beans <- rep(c("Arabica","Liberica", "Robusta"), each = 4)
beans
## [1] "Arabica" "Arabica" "Arabica" "Arabica" "Liberica" "Liberica"
## [7] "Liberica" "Liberica" "Robusta" "Robusta" "Robusta" "Robusta"
## randomly sample the character vector to give the order of coffees
set.seed(1234) ## this is ONLY for consistency, remove if doing this yourself
allocation <- sample(beans, 12)
allocation
## [1] "Robusta" "Robusta" "Liberica" "Liberica" "Arabica" "Liberica"
## [7] "Arabica" "Robusta" "Arabica" "Liberica" "Robusta" "Arabica"Having run the code above your CRD plan is as follows
| Cup | Bean |
|---|---|
| 1 | Robusta |
| 2 | Robusta |
| 3 | Liberica |
| 4 | Liberica |
| 5 | Arabica |
| 6 | Liberica |
| 7 | Arabica |
| 8 | Robusta |
| 9 | Arabica |
| 10 | Liberica |
| 11 | Robusta |
| 12 | Arabica |
R code above, but this time choose a different random seed by choosing a different number in this line of code set.seed(1234). What is your CRD plan? Why might keeping the random seed be important?
Randomised complete block design (RCBD)
Let’s consider a randomized complete block design with one treatment factor (e.g., coffee bean type). If the treatment factor has \(t\) levels there will be \(b\) blocks that each contain \(t\) experimental units resulting in a total of \(t\times b\) experimental units. For example, let’s imagine that for the coffee experiment we had two cup types: mugs and heatproof glasses. We might consider the type of receptacle to have an effect on the coffee strength measured, however, we are not interested in this. Therefore, to negate this we block by cup type. This means that any effect due to the blocking factor (cup type) is accounted for by the blocking.
For a blocked design we want the \(t\) experimental units within each block should be as homogeneous as possible (as similar as possible, so that there is unlikely to be unwanted variation coming into the experiment this way). The variation between blocks (the groups of experimental units) should be large enough (i.e., blocking factors different enough) so that conclusions can be drawn. Allocation of treatments to experimental units is done randomly (i.e., treatments are randomly assigned to units) within each block.

Designing a RCBD using R
Let’s assume you want to set up an experiment similar to the CRD one above; however, now you are in the situation where you have two types of cups (mugs and heatproof glasses). Below we use R to do the random allocation of treatments within each block (cup type) for you.
Here we have \(t = 3\) treatments (bean types) and \(b = 2\) blocks (cup types) so we will have \(t \times b = 6\) experimental units in total.
set.seed(4321) ## this is ONLY for consistency, remove if doing this yourself
plan <- data.frame(Beans = rep(c("Arabica","Liberica", "Robusta"), times = 2),
Block = rep(c("Mug", "Glass"), each = 3)) %>% ## combine experiment variables
group_by(Block) %>% ## group by blocking factor
dplyr::sample_n(3)
plan
## # A tibble: 6 × 2
## # Groups: Block [2]
## Beans Block
## <chr> <chr>
## 1 Arabica Glass
## 2 Liberica Glass
## 3 Robusta Glass
## 4 Liberica Mug
## 5 Arabica Mug
## 6 Robusta MugHaving run the code above your RCBD plan is as follows
| Receptacle | 1 | 2 | 3 | 1 | 2 | 3 |
| Beans | Arabica | Liberica | Robusta | Liberica | Arabica | Robusta |
| Block | Glass | Glass | Glass | Mug | Mug | Mug |
R code above, but this time choose a different random seed by choosing a different number in this line of code set.seed(4321). What is your CRD plan? Why might keeping the random seed be important?
Factorial design
A factorial experiment is one where there are two or more sets of (factor) treatments7. Rather than studying each factor separately all combinations of the treatment factors are considered. Factorial designs enable us to infer any interaction effects, which may be present. An interaction effect is one where the effect of one variable depends on the value of another variable (i.e., the effect of one treatment factor on the response variable will change depending on the value of a second treatment factor.)
Let’s consider Dr Java’s experiment above. Here, Dr Java wants to study all combinations of the levels of each factor. Their objective is to determine what type of grind and brew ratio (i.e., amount of coffee in relation to water) leads to the strongest coffee.
Possible outcomes
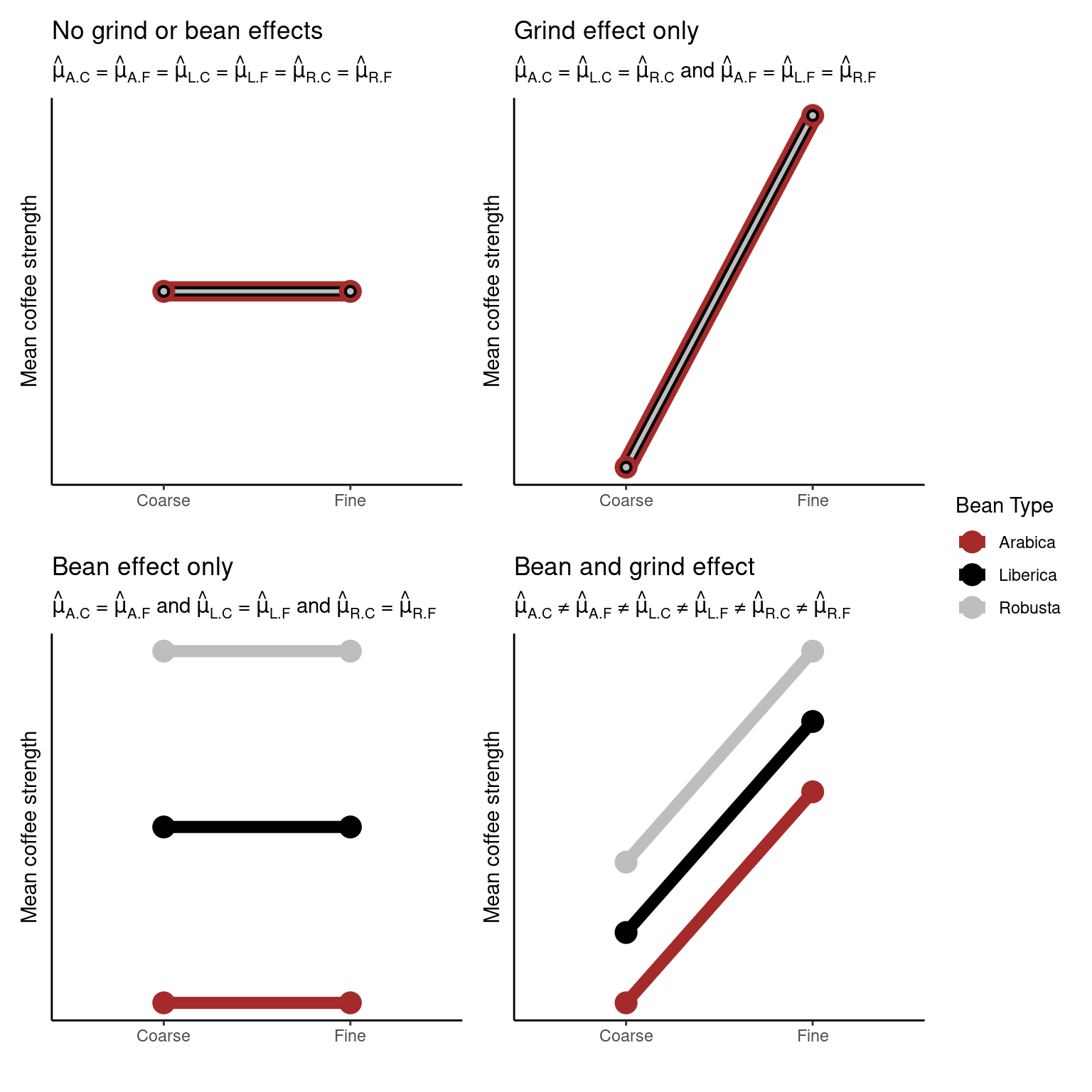
Interactions
If an interaction effect exists the effect of one factor on the response will change depending on the level of the other factor.
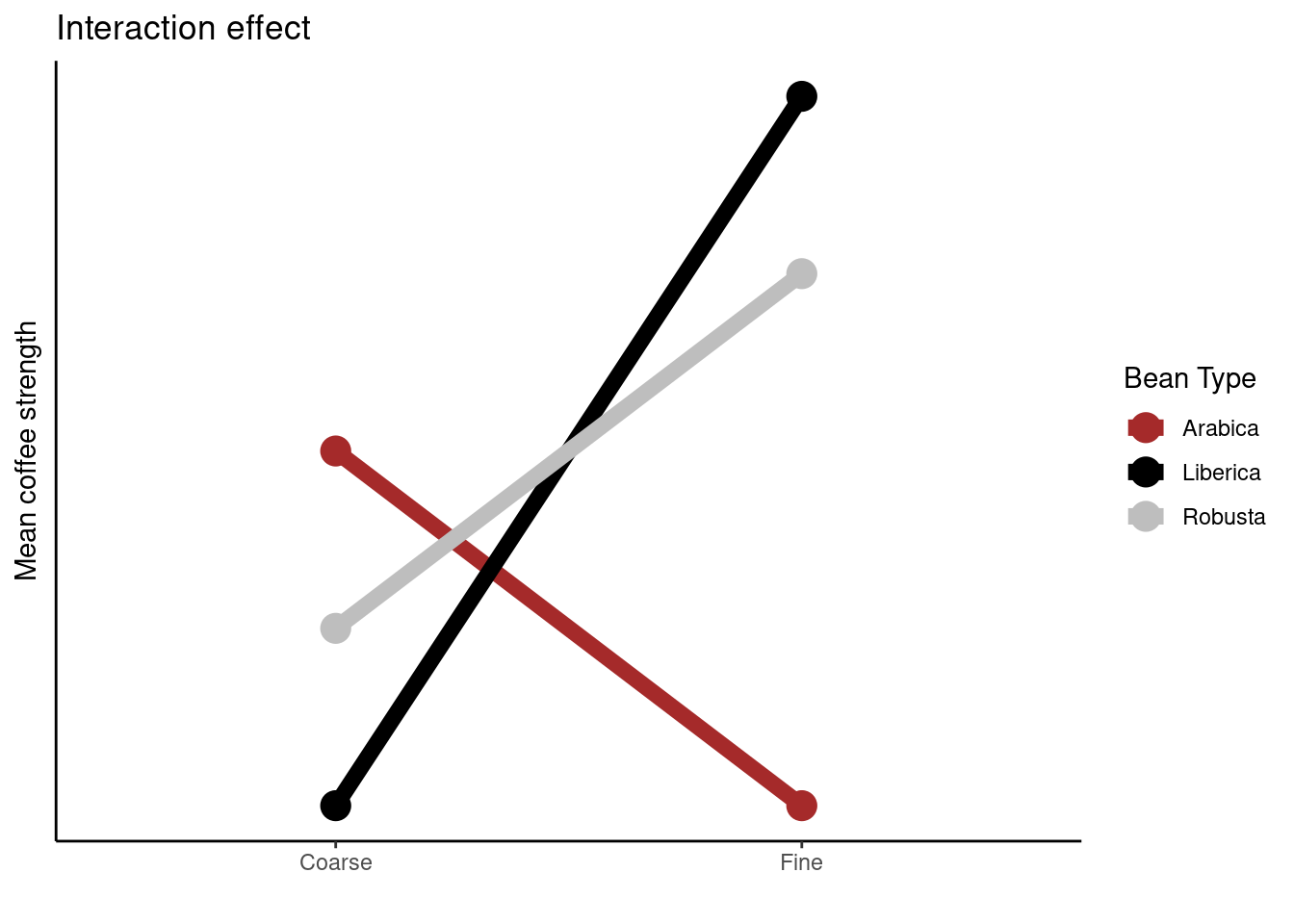
The plot above is called an interaction plot. Creating such a plot is often very useful when drawing inference; in this instance we can see that the strength of the coffee changes depending on the type of coffee bean used, however, this relationship differs depending on the type of grind used. For example, Liberica beans produce stronger coffee than the other two beans when the fine grind is used, but weaker coffee when the coarse grind is used.
Designing factorial experiment using R
Here we use the R package edibble which is specifically designed to aid in the planning and designing of experiments.
## Factorial design (Brew and Grind)
design("Barista Brew: Factorial Design") %>%
set_units(cup = 12) %>% # 2*2*3
set_trts(BrewRatio = c("2-1", "1-1", "1-2"),
Grind = c("Fine", "Coarse")) %>%
allot_trts(~cup) %>%
assign_trts("random", seed = 836) %>% ## the random seed for random allocation
serve_table()
## # Barista Brew: Factorial Design
## # An edibble: 12 x 3
## cup BrewRatio Grind
## <U(12)> <T(3)> <T(2)>
## <chr> <chr> <chr>
## 1 cup01 1-2 Fine
## 2 cup02 2-1 Coarse
## 3 cup03 1-1 Fine
## 4 cup04 2-1 Coarse
## 5 cup05 1-2 Coarse
## 6 cup06 1-1 Coarse
## 7 cup07 1-2 Fine
## 8 cup08 1-1 Fine
## 9 cup09 1-2 Coarse
## 10 cup10 1-1 Coarse
## 11 cup11 2-1 Fine
## 12 cup12 2-1 FineR code above, but this time choose a different random seed (by changing seed = 836). What is your design? Now increase the number of replications, use your R skills to figure out what line of code needs changing here. What is your design now?
Note is a factorial design has equal numbers of replicates in each group then it is said to be a balanced design; if this is not the case then it is unbalanced.↩︎